
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 코드블럭 오류
- 본즈앤올
- #endif
- 연산자
- Machine Learning
- 형변환
- 단항연산자
- C++
- standford University
- classification problem
- algorithm
- regression problem
- 프로그래밍
- Andrew Ng
- #define
- 기계학습
- CLion
- 코딩테스트
- coursera
- 학습 알고리즘
- Greedy
- const
- Runtime constants
- decimal
- 이코테
- 나동빈님
- sizeof()
- compile time constants
- 기계학습 기초
- 홍정모님
- Today
- Total
wellcome_공부일기
1. Introduction - Supervised learning 본문
* 해당 글은 coursera의 Machine Learning by Andrew Ng 강의를 토대로 작성되었습니다.
1. Introduction - Supervised learning
<목차>
1. Housing price prediction 문제 예시
- Supervised learning :: regression problem(회귀문제)
2. Breast cancer 문제 예시
- Supervised learning :: clasiffication problem(분류문제)
3. Supervised learning QUIZ
4. Summary
1. Housing price prediction 문제 예시
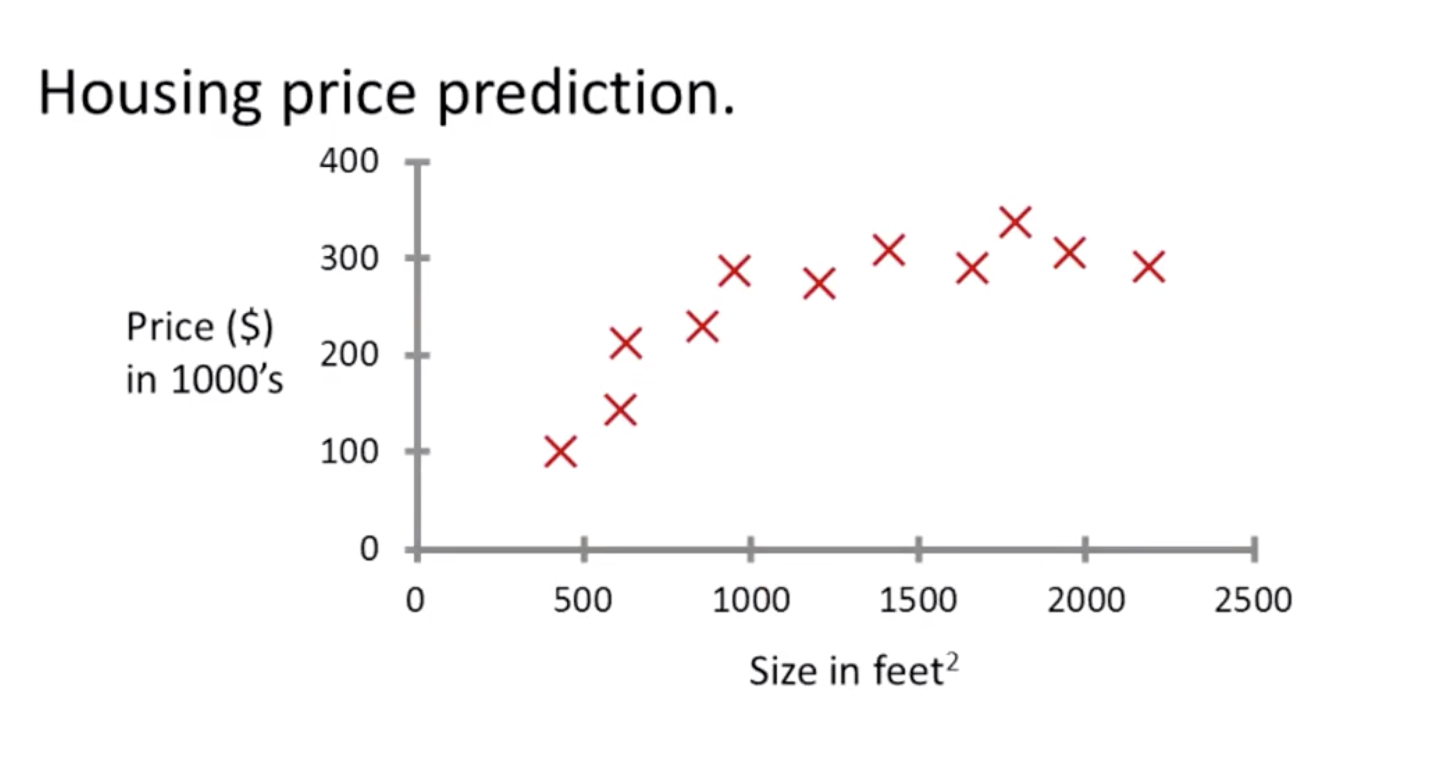
- 데이터를 수집한 것으로 데이터 집합을 위 표와 표현한 것을 도식화라고 함
- 가로 축에는 서로 다른 주택의 크기가 제곱피트 단위
- 세로 축에는 서로 다른 주택의 가격이 천 달러 단위로 표시
< 어떤 친구가 750 제곱피트짜리 집을 소유하고 있고 그 집을 판매하려 할때 얼마에 팔수 있을까?>
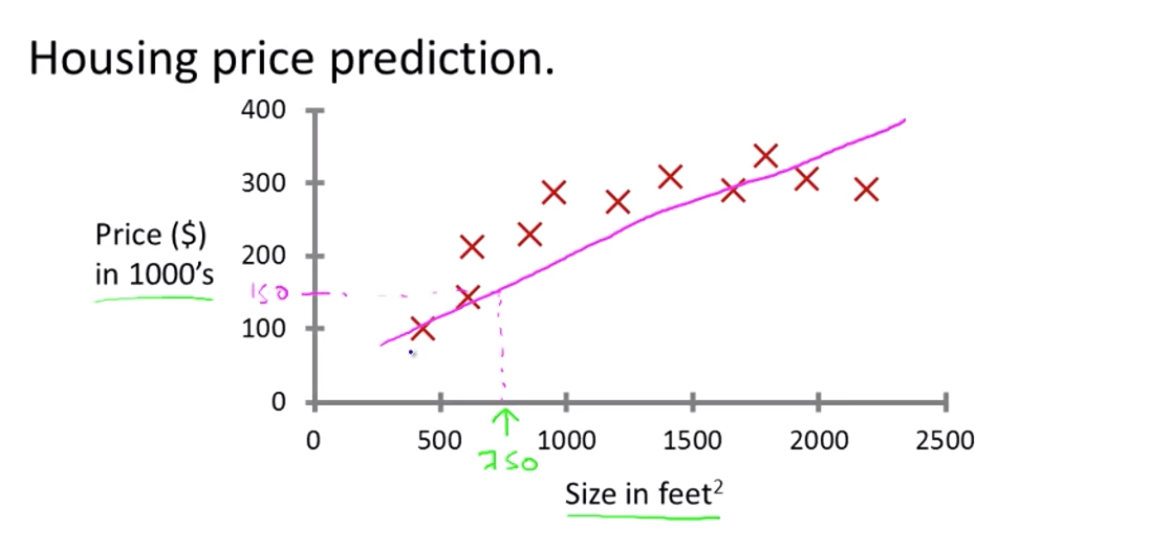
1. 데이터를 통과하는 직선을 그리기
- 학습 알고리즘의 방식 중 하나
- 직선 하나를 데이터에 맞추는 것(fit) 이를 통해 보면 집을 15만 달러정도에 팔 수 있음
- 하지만 이보다 더 좋은 학습 알고리즘이 있음
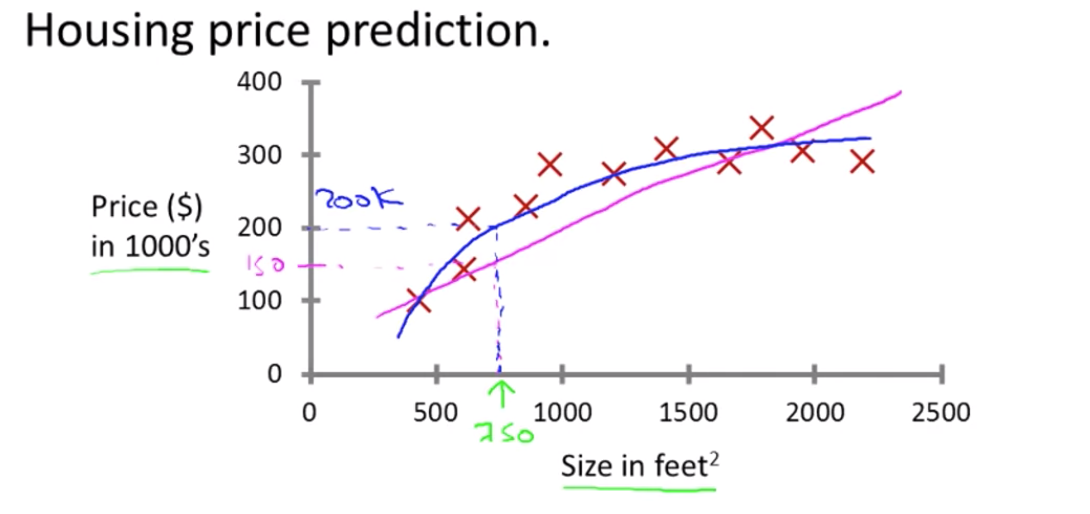
2. 이차함수를 데이터에 맞추기
- 직선을 데이터에 맞추는 대신 이차함수를 데이터에 맞추는 것이 나음(200k로 더 정확한 예측 가능)
- 후에는 직선 vs 이차 함수 판단을 해야할 때가 있음
지도학습(Supervised learning)이 어떻게 쓰였을까?
- Supervised learning :: regression problem(회귀문제)
일단 지도학습이란 우리가 알고리즘에게 데이터 집합을 제공하는데, 각 데이터에 정답이 포함
ex) 집에 대한 데이터 집합을 제공했는데, 각 집마다 정확한 가격도 알려주는 것
= 그 집에 매매된 실제 가격을 알려줌
알고리즘은 그 '정답'을 더 많이 만들어내는 것
=친구가 판매하려 하는 집에 대한 것도 포함
이는 회귀 문제(regression problem)라고도 함
회귀 문제는 연속된 값을 가진 결과를 예측한다는 것을 의미 ex) 연속된 값 = 가격
원래 가격은 반올림해서 표현함으로 불연속적이지만 보통은 집값을 실수(scala)로, 연속적인 값으로
생각함
그래서 회귀라는 용어는 우리가 이런 연속이라는 특징을 가진 값을 예측하려고 한다는 것을 의미
회귀문제(regression problem)말고도 분류문제(classification problem)도 존재
2. Breast cancer 문제 예시
- Supervised learning :: clasiffication problem(분류문제)
- 가로 축은 종양의 크기
- 세로 축은 1 또는 0으로 yes or no
만약 종양이 악성이면 1, 양성이면 0
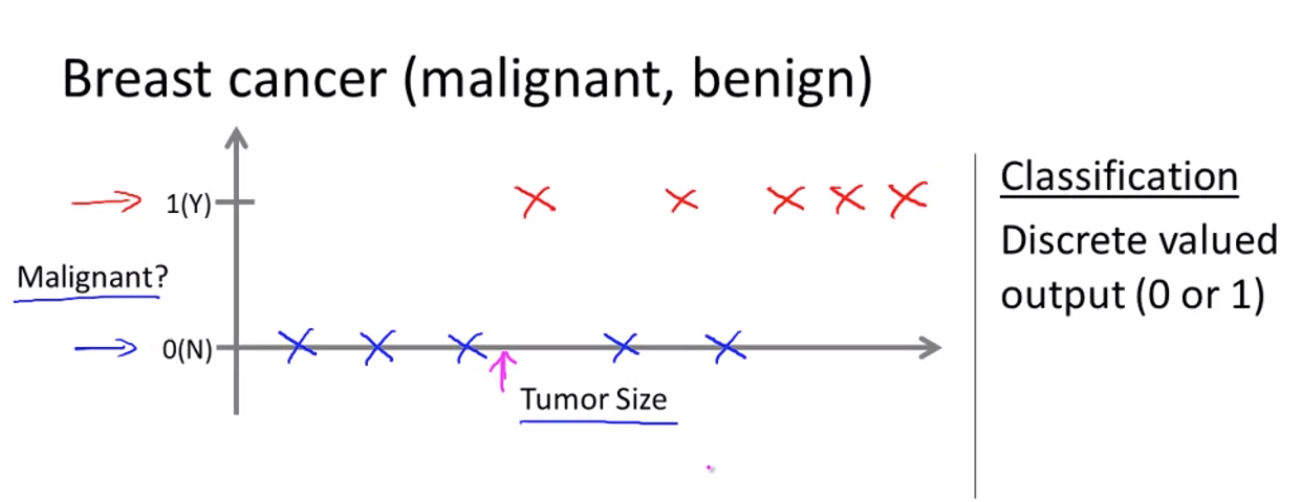
- 위 화살표는 종양의 크기가 이 정도일때 종양이 악성인지 양성인지 예상해볼 수 있는 지표
- 이것은 분류문제(classification problem)로 분류는 0 또는 1, 악성 또는 양성과 같이 불연속적인 결과값을 예측한다는 뜻
하지만, 어떤 분류 문제는 결과가 두개(악성/양성)보다 많을 수 있음
예를 들어, 유방암에는 3가지 종류가 있을 수도 있고 0, 1, 2, 3이라는 불연속적인 값을 예측
0은 양성 종양, 1은 첫번째 종류의 암, 2는 두번째 종류의 암 etc.
이렇게 결과값을 분류하는 것은 분류문제(classification problem)로 볼수 있음->이산적이기 때문
분류 문제에서는 위 처럼 2가지 결과값 예측 말고 단 하나의 특성(feature), 또는 속성(attribute)을 이용한 도식화
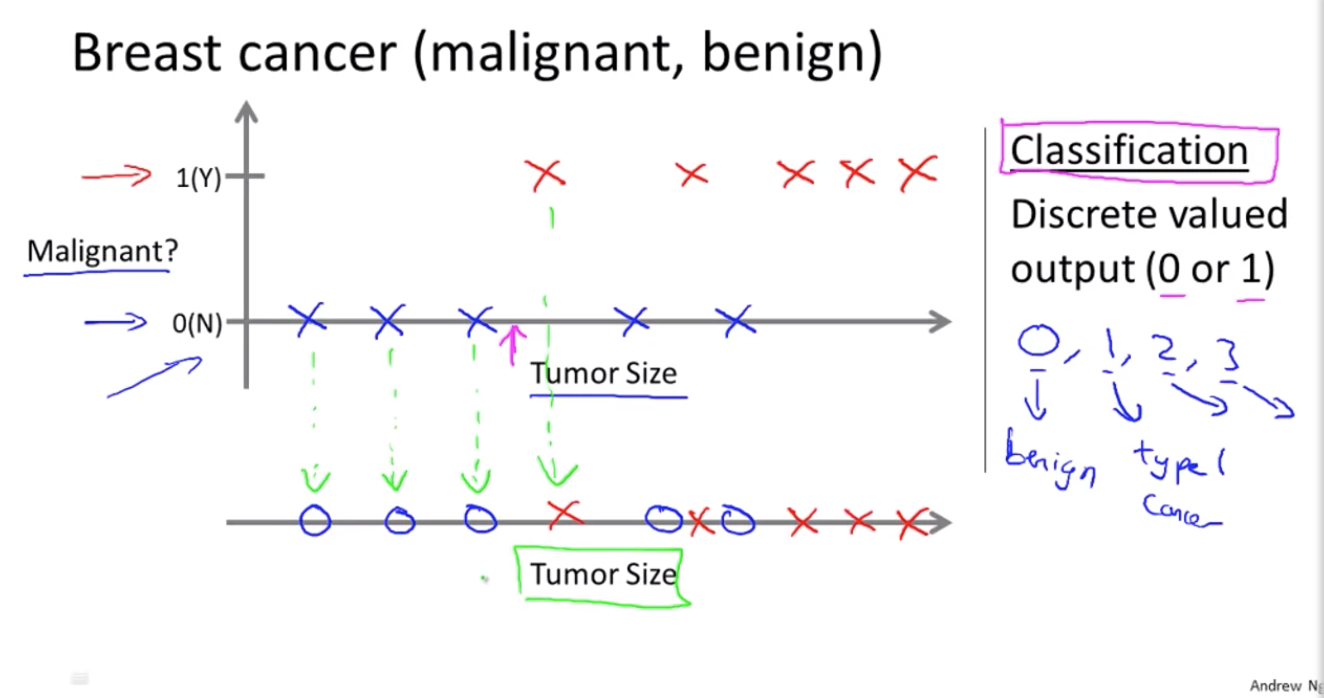
- 종양의 크기라는 속성만으로 악성인지 양성인지 예측할려고 한다면 데이터 도식화는 위처럼 됨
- 동그라미는 악성 가위표는 양성을 나타냄
- 이 예시에서는 단 하나의 특성(feature), 또는 속성(attribute)를 사용
- 즉 종양의 크기로 종양이 악성인지 양성인지 예측하는 모델
어떤 기계학습은 하나의 이상의 특징/한개 이상의 속성이 주어짐
아래는 나이, 종야의 크기라는 두개의 속성으로 종양을 예측하는 모델
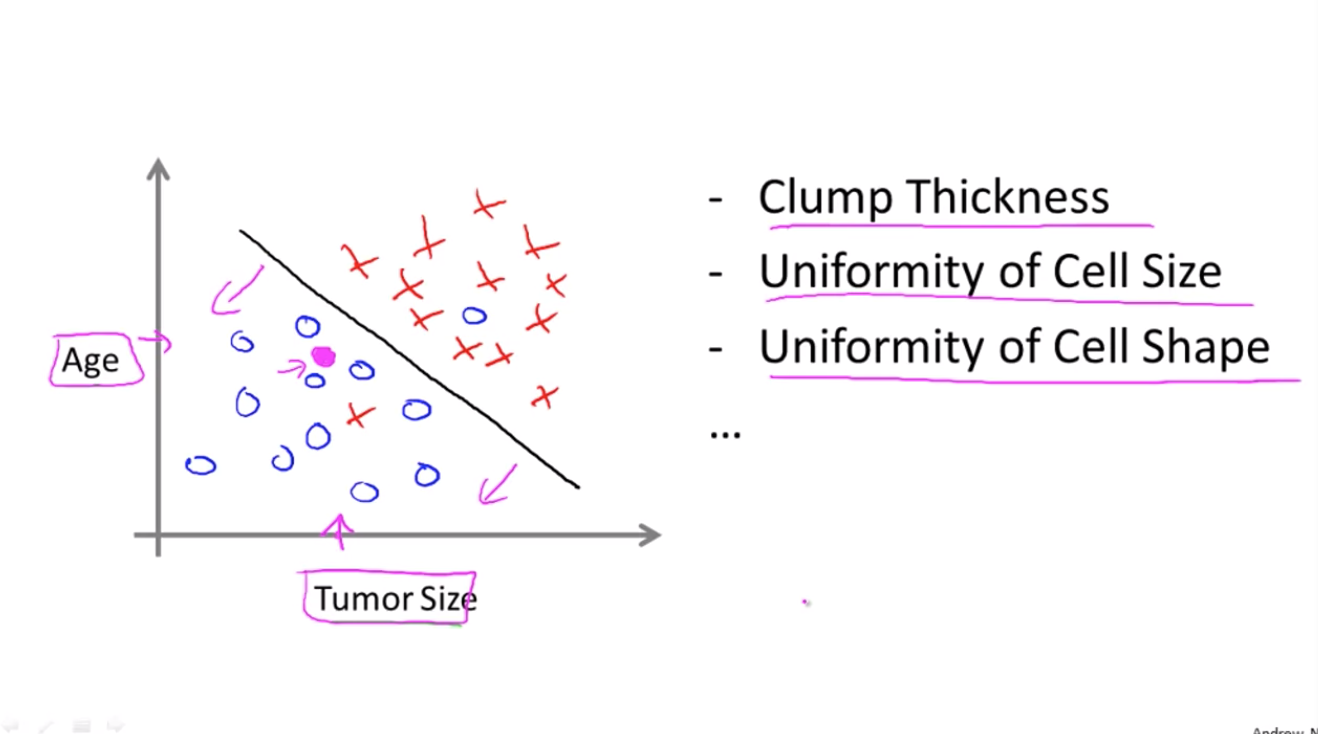
- 나이와 종양크기로 종양이 악성인지 양성인지 예측하는 그래프
- 학습 알고리즘에 직선을 하나 그으면 두 종류의 종양을 구분할 수 있음
- 특성이 2개로 환자의 나이와 종양크기가 있지만 다른 기계학습 문제에서는 더 많은 특성이 있는 경우가 잦음
ex) 종양의 두께, 종양 세포 크기의 일관성, 종양 세포의 모양의 일관성 등등
어떤 학습 문제에서 고작 세개 다섯개만 다뤄도 되지만, 무한히 많은 특성/속성을 다뤄야 할 필요가 있음
=> 그래야 학습 알고리즘이 수많은 속성 또는 특성이나 신호(cue)를 통해 예측가능
하지만, 무한대의 개수 특성을 컴퓨터 메모리에 저장하게 되면 컴퓨터 메모리의 용량을 다써버리게 될 수 있음
Support Vector Machine이라는 알고리즘에서 깔끔한 수학적 방법을 사용하면 컴퓨터가 무한한 개수의 특성을 다룰 수 있음
3. Supervised learning QUIZ

정답:
1. 회귀문제
물건이 수천이나 있어서 이걸 실수(real number)로, 연속적인 값으로 봄
내가 팔려는 물건이 연속적인 값이다.
2. 분류문제
예측하고자하는 값을 0으로 설정하여 계정이 해킹 당하지 않음을, 1이면 해킹당했음을 나타냄
알고리즘은 이 두 이산적인 값을 예측하고 이산적인 값의 수가 적기 때문에 분류문제로 다룰 것임
4. Summary
Supervised Learning
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
Supervised learning problems are categorized into "regression" and "classification" problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
Example 1:
Given data about the size of houses on the real estate market, try to predict their price. Price as a function of size is a continuous output, so this is a regression problem.
We could turn this example into a classification problem by instead making our output about whether the house "sells for more or less than the asking price." Here we are classifying the houses based on price into two discrete categories.
Example 2:
(a) Regression - Given a picture of a person, we have to predict their age on the basis of the given picture
(b) Classification - Given a patient with a tumor, we have to predict whether the tumor is malignant or benign.
Summary
지도 학습: 데이터 집합 안에 있는 모든 예시에 대해 알고리즘이 예측해냈으면 하는 정답을 우리가 얻는것
회귀문제 : 회귀는 우리의 연속적인 출력값을 예측
분류문제: 분류는 이산적인 출력값을 예측
'컴퓨터 과학 > 머신러닝' 카테고리의 다른 글
| 2. Model and Cost Function- Cost Function (0) | 2020.06.11 |
|---|---|
| 2. Model and Cost Function - Model Representation (0) | 2020.06.05 |
| 1. Introduction- Unsupervised Learning (0) | 2020.06.04 |
| 1. Introduction - What is Machine Learning? (0) | 2020.06.03 |
| 1. Introduction- Welcome (0) | 2020.06.03 |

