
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 기계학습 기초
- classification problem
- 본즈앤올
- C++
- #endif
- 프로그래밍
- 나동빈님
- 학습 알고리즘
- 단항연산자
- compile time constants
- algorithm
- 이코테
- 기계학습
- standford University
- Greedy
- Runtime constants
- #define
- 코딩테스트
- 연산자
- decimal
- const
- 코드블럭 오류
- regression problem
- 형변환
- sizeof()
- CLion
- Andrew Ng
- 홍정모님
- coursera
- Machine Learning
- Today
- Total
wellcome_공부일기
1. Introduction- Unsupervised Learning 본문
* 해당 글은 coursera의 Machine Learning by Andrew Ng 강의를 토대로 작성되었습니다.
1. Introduction- Unsupervised Learning
<목차>
1. Unsupervised learning이란?
2. Unsupervised learning 예
3. Unsupervised learning QUIZ
4. Summary
1. Unsupervised learning이란?
어떤 레이블도 갖고 있지 않거나, 모두 같은 레이블을 갖고 있거나,또는 아예 레이블이 없는 상태
그래서 우리에게 주어진 데이터 집합에 우리는 이것으로 무엇을 할지, 또 각 데이터가 무엇인지 알 수 없습니다
"여기 데이터가 있는데, 여기서 어떤 구조를 찾을 수 있지?"
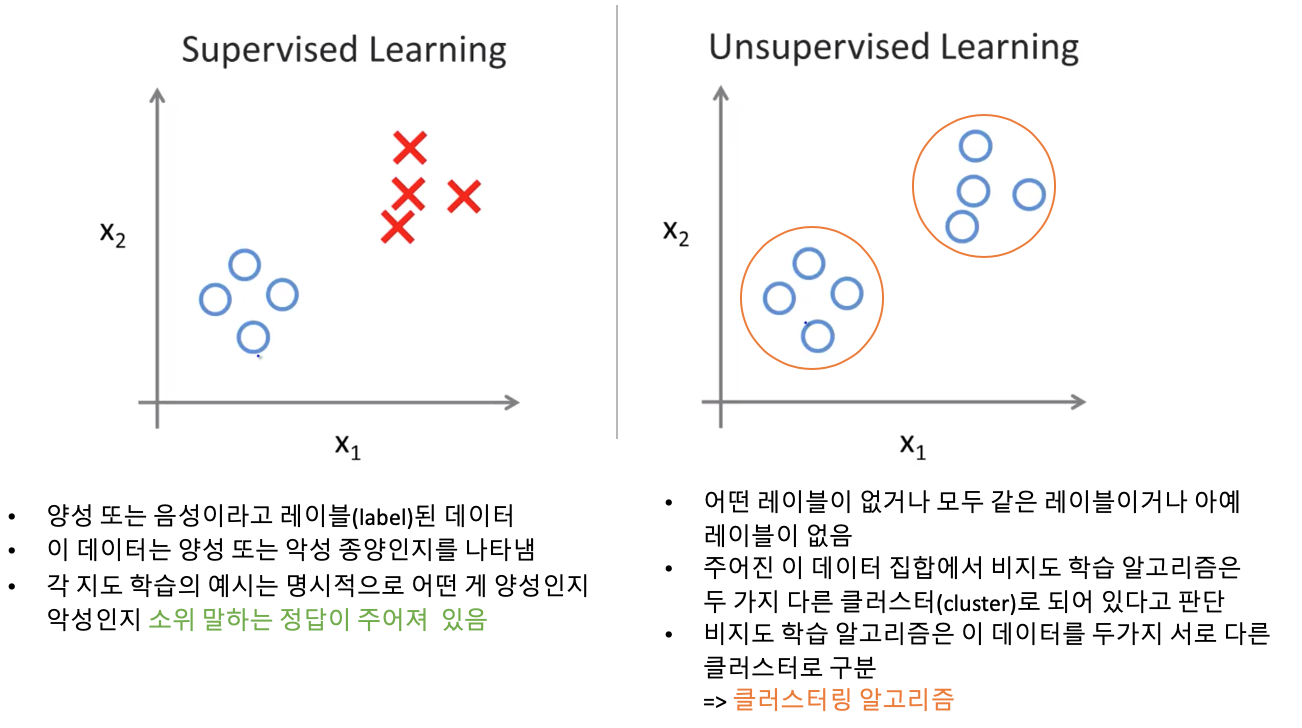
2. Unsupervised learning 예
클러스터링 알고리즘(Clustering Algorithms)과 비지도 학습 알고리즘
- 구글 뉴스(news.google.com)
같은 토픽의 모든 기사들을 같이 묶여 표시
매일 새로운 수천 가지의 새로운 기사들을 조사하여 자동적으로 연관된 기사를 묶여줌
- DNA 미세배열
그룹 내의 개인마다 특정 유전자가 얼마나 발현되었는지 측정
클러스터링 알고리즘을 통해 사람들을 서로 다른 타입으로 묶을 수 있음
ex) 이 사람들은 1번 타입, 저 사람들은 2번 타입
- 대규모 컴퓨터 클러스터를 구성(Organize computing clusters)
어떤 기기들끼리 주로 같이 일하는지 알아냄
만약 그 기기들을 같이 둔다면 data centers를 더 효율적이게 만들 수 있음
- 소셜 네트워크 분석(Social network analysis)
누구에게 가장 이메일을 많이 보내는지,
친구추천 정보를 줄때 자동적으로 어떤 게 적절한 친구 그룹인지,
서로서로 다 아는 사람들의 그룹인지를 찾을 수 있는지 분석
- 시장 세분화(Market segmentation)
많은 회사는 고객 정보의 거대한 데이터베이스를 가지고 있음
이 고객에 대한 데이터 집합을 보고 자동적으로 세분화된 시장을 찾음
: 자동적으로 고객들을 세분화된 시장 안으로 묶어 넣어 판매와 영업을 동시에 수행
고객의 정보는 가지지만 미리 세분화된 시장을 알지 못했음
-> 알고리즘이 스스로 데이터로부터 알아낸 사실
- 천문학 데이터 분석(Astronomical data analysis)
은하계 생성에 관한 이론에 클러스터링 알고리즘이 사용
- 칵테일 파티 문제(Cocktail party problem)
중첩된 소리를 칵테일 파티 알고리즘이 두 음성이 더해졌다는 사실을 알고,
나아가 이 두 음성 소스를 분리해줄 수 있음

Octave 소프트웨어로 구현된 코드로 SVD함수는 특이값 분해(singular value decomposition)의 약자
Octave에 내장된 함수로 Matlab 등을 사용하면 다른 언어(C++, Java ..)보다 학습 알고리즘을 빨리 구현할 수 있음
3. Unsupervised learning QUIZ

정답
2번, 3번: 비지도 학습은 데이터에 정답이 존재하지 않는다.
주어진 데이터를 자동으로 그룹으로 묶는다. -> 비지도 학습
오답
1번: 비지도 학습은 레이블이 존재하지 않을 수 있다.
스팸인지 아닌지 레이블된 데이터를 가지고 있으면 지도학습으로 다뤄짐
4번: 전에 유방암 예시와 같은 것으로 지도학습 문제로 풀게 됨
4. Summary
Unsupervised Learning
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don't necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results.
Example:
Clustering: Take a collection of 1,000,000 different genes, and find a way to automatically group these genes into groups that are somehow similar or related by different variables, such as lifespan, location, roles, and so on.
Non-clustering: The "Cocktail Party Algorithm", allows you to find structure in a chaotic environment. (i.e. identifying individual voices and music from a mesh of sounds at a cocktail party).
'컴퓨터 과학 > 머신러닝' 카테고리의 다른 글
| 2. Model and Cost Function- Cost Function (0) | 2020.06.11 |
|---|---|
| 2. Model and Cost Function - Model Representation (0) | 2020.06.05 |
| 1. Introduction - Supervised learning (0) | 2020.06.04 |
| 1. Introduction - What is Machine Learning? (0) | 2020.06.03 |
| 1. Introduction- Welcome (0) | 2020.06.03 |


